可靠的邢台做网站/优化建站
TAILQ双向有尾链表的详解
- 常见的链表结构
- 1.SLIST
- 2.STAILQ
- 3.LIST
- 4.TAILQ
- 5.CIRCLEQ
- 一、TAILQ链表简介
- 二、TAILQ的定义和声明
- 三、TAILQ队列的函数
- 1.链表头的初始化
- 2.获取第一个节点地址
- 3.获取最后一个节点地址
- 4.链表是否为空
- 5.下一个节点地址
- 6.上一个节点地址
- 7.插入头节点
- 8.插入尾节点
- 9.高效获取链表的最后一个节点地址
- 10.移除节点
- 11.遍历链表所有节点(只能读)
- 12.安全的遍历链表节点
- 其他的函数
- 四、TAILQ的使用
TAILQ是 Tail Queue 的缩写,意为双向有尾链表,是FreeBSD中的一个队列宏,属于 sys/queue.h 头文件的一部分,用于实现双向队列数据结构。
常见的链表结构
在 sys/queue.h 文件定义了5种链表结构,他们的结构分别如下:
1.SLIST
singly-linked list,意为单向无尾链表;
注意:“单向无尾链表”中的无尾通常指的是链表的实现中没有维护指向尾节点(最后一个节点)的指针

2.STAILQ
Singly-linked Tail queue,单向有尾链表;

3.LIST
双向无尾链表

4.TAILQ
Tail queue, 双向有尾链表
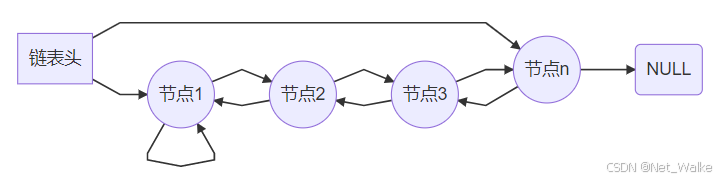
5.CIRCLEQ
双向循环链表
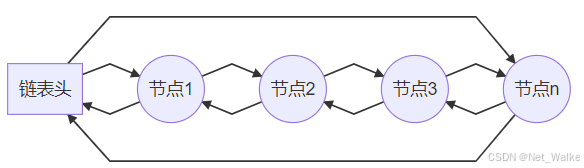
TAILQ 的设计类似于维护头尾指针的优化双向链表,所有头尾操作均为 O(1),通过二级指针(tqe_prev)进一步优化了删除和插入逻辑,避免了显式依赖前驱节点的位置。
一、TAILQ链表简介
TAILQ的链表结构图如下:
TAILQ 链表介绍:
* A tail queue is headed by a pair of pointers, one to the head of the
* list and the other to the tail of the list. The elements are doubly
* linked so that an arbitrary element can be removed without a need to
* traverse the list. New elements can be added to the list before or
* after an existing element, at the head of the list, or at the end of
* the list. A tail queue may be traversed in either direction.
由于具有在头部或尾部插入、删除节点的操作时间复杂度均为 O(1) ,适合于高频队列操作(如消息队列、任务调度等)
二、TAILQ的定义和声明
- 节点中需要包含 TAILQ_ENTRY(type) 这一个字段。
#define TAILQ_ENTRY(type) \
struct { \struct type *tqe_next; /* next element */ \struct type **tqe_prev; /* address of previous next element */
}
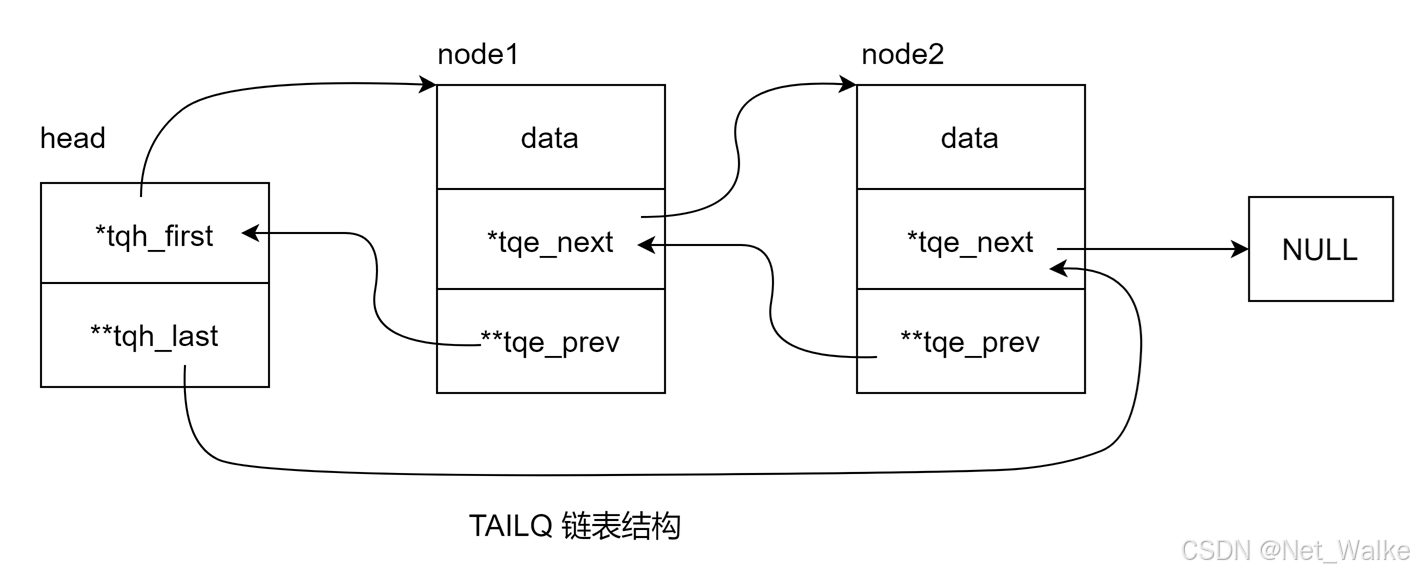
tqe_next 指向的是下一个节点的地址,而 tqe_prev 为一个二级指针,指向的是前一个节点的 tqe_next (指针)的地址,解引用之后, (*tqe_next )表示的就是当前节点的地址。
- 保存首尾信息的链表头声明
TAILQ队列中需要记录头节点和尾节点的地址,因此定义了HEAD结构:
#define TAILQ_HEAD(name, type) \
struct name { \struct type *tqh_first; /* first element */ \ /* 指向第一个节点 */struct type **tqh_last; /* addr of last next element */ /* 指向最后一个节点的 tqe_next 字段地址 */
}
同样的,tqh_last 为二级指针,指向的是最后一个节点的指针的地址,同上,解引用之后,获取到尾节点地址(*tqh_last)。
三、TAILQ队列的函数
1.链表头的初始化
#define TAILQ_INIT(head) do { \(head)->tqh_first = NULL; \(head)->tqh_last = &(head)->tqh_first; \
} while (0)
head 表示链表头地址,可以看到,初始化时队列为空时,tqh_last 指针指向的是 tqh_first 的地址。
2.获取第一个节点地址
#define TAILQ_FIRST(head) ((head)->tqh_first) // 第一个元素地址
3.获取最后一个节点地址
#define TAILQ_LAST(head, headname) \(*(((struct headname *)((head)->tqh_last))->tqh_last)) // 最后一个元素地址
这个宏定义我们可以看到有两个**tqh_last** ,以下逐步解释这个宏的实现:
-
tqh_last的指向:链表头的tqh_last字段指向最后一个节点的tqe_next字段的地址,(head)->tqh_last)表示的是最后一个节点的tqe_next字段的地址,当然最后一个节点tqe_next指针指向的为NULL。 -
强制类型转换: 由于 TAILQ_HEAD的结构体和TAILQ_ENTRY结构体分布一样,这里可以将
(head)->tqh_last)地址强制转换为 TAILQ_HEAD 的类型,因此((struct headname *)((head)->tqh_last))就等同于((struct entries*)(&tqe_next);因此再获取tqh_last地址便是获取节点中tqe_prev的地址。
最终的结果就是:当强制转换后,(((struct headname *)((head)->tqh_last))->tqh_last) 就是 &node->entries.tqe_prev。
- 解引用:最后解引用就能得到最后一个节点的地址。
下面该示意图可以参考:

这里有点啰嗦,总之就是:将节点的 tqe_next 字段地址假装成链表头的地址,以便后续访问继续使用链表头结构体的字段。
4.链表是否为空
#define TAILQ_EMPTY(head) ((head)->tqh_first == NULL)
5.下一个节点地址
#define TAILQ_NEXT(elm, field) ((elm)->field.tqe_next)
6.上一个节点地址
#define TAILQ_PREV(elm, headname, field) \(*(((struct headname *)((elm)->field.tqe_prev))->tqh_last))
这里和前面获取最后一个节点地址的原理一样。
7.插入头节点
#define TAILQ_INSERT_HEAD(head, elm, field) do { \if ((TAILQ_NEXT((elm), field) = TAILQ_FIRST((head))) != NULL) \ // 如果head不为空,则插入到首节点TAILQ_FIRST((head))->field.tqe_prev = \&TAILQ_NEXT((elm), field); \else \(head)->tqh_last = &TAILQ_NEXT((elm), field); \ // 如果head为空,则elm指向的是第一个节点TAILQ_FIRST((head)) = (elm); \(elm)->field.tqe_prev = &TAILQ_FIRST((head)); \
} while (0)
如果队列不为空,则操作流程示意如下:
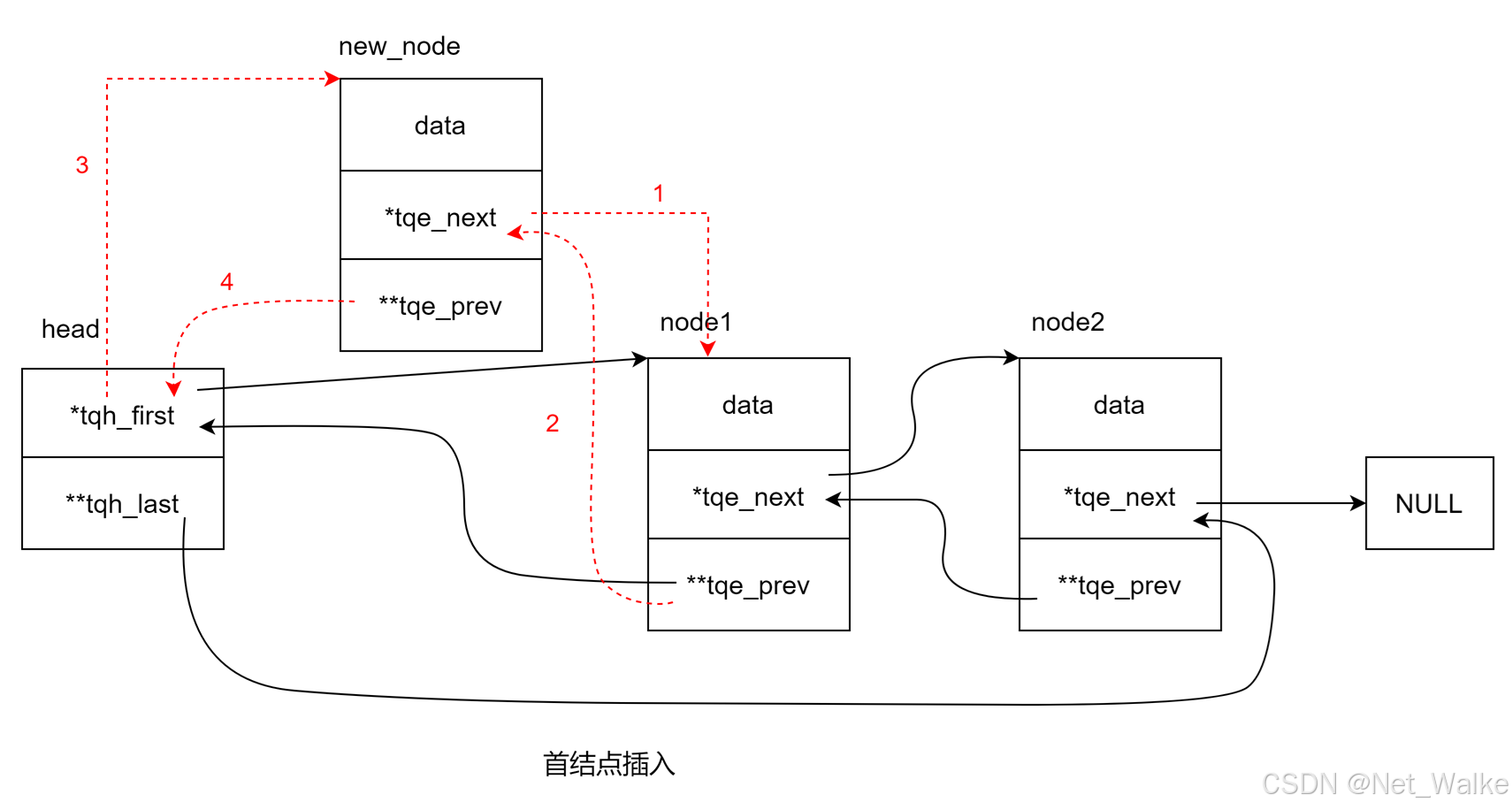
8.插入尾节点
#define TAILQ_INSERT_TAIL(head, elm, field) do { \QMD_TAILQ_CHECK_TAIL(head, field); \TAILQ_NEXT((elm), field) = NULL; \ /* 新节点的next指针为NULL; */(elm)->field.tqe_prev = (head)->tqh_last;\/*新节点的tqe_prev指针赋值为(head)->tqh_last;*/*(head)->tqh_last = (elm);\ /* *((head)->tqh_last) = (elm); 把尾巴节点的tqe_next指向新节点elm*/(head)->tqh_last = &TAILQ_NEXT((elm), field);\ /* 更新链表头的尾指针地址 */
} while (0)
9.高效获取链表的最后一个节点地址
#define TAILQ_LAST_FAST(head, type, field) \(TAILQ_EMPTY(head) ? NULL : __containerof((head)->tqh_last, QUEUE_TYPEOF(type), field.tqe_next))
展开得到下面的宏定义:
#define TAILQ_LAST_FAST(head, type, field) \(TAILQ_EMPTY(head) ? NULL : \((type *)((char *)((head)->tqh_last) - offsetof(type, field.tqe_next)))
其中,type为节点的类型名,field为节点中tqe_next所属的字段名。
操作流程:
(head)->tqh_last:
链表头的tqh_last字段指向最后一个节点的tqe_next字段地址(例如&nodeN->field.tqe_next)。offsetof(type, field.tqe_next):
计算tqe_next字段在节点结构体type中的偏移量(字节数)。- 指针运算:
将(head)->tqh_last(类型为char*)减去tqe_next字段的偏移量,得到节点自身的起始地址。 - 类型转换:
将结果转换为type*(节点类型指针),即最后一个节点的地址。
与 TAILQ_LAST 的对比
| 宏 | 实现方式 | 性能 | 适用场景 |
|---|---|---|---|
TAILQ_LAST | 通过链表头的 tqh_last 字段解引用两次,依赖结构体内存布局的间接操作 | 较慢 | 标准实现,兼容性强 |
TAILQ_LAST_FAST | 直接通过指针偏移计算节点地址,减少解引用层级 | 更快 | 需要高频访问尾节点的优化场景 |
性能优势:
- 减少解引用次数:
TAILQ_LAST需要两次解引用(head->tqh_last和tqe_prev),而TAILQ_LAST_FAST直接通过指针运算定位节点地址。 - 避免类型转换风险:直接计算偏移量,无需依赖链表头和节点字段的内存布局一致性。
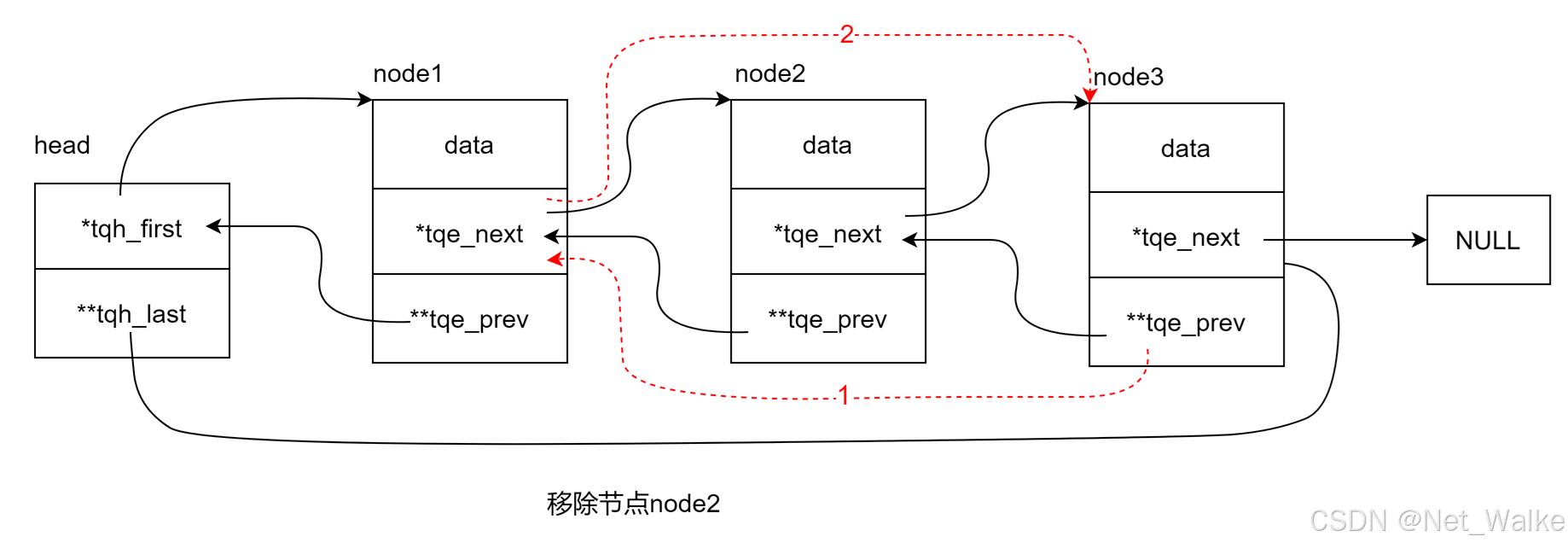
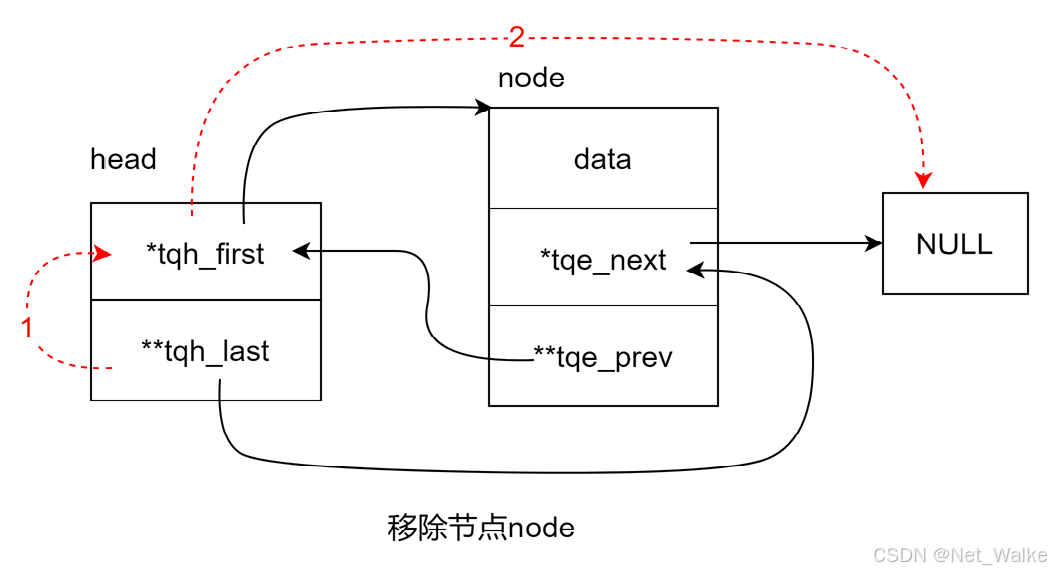
10.移除节点
#define TAILQ_REMOVE(head, elm, field) do { \if ((TAILQ_NEXT((elm), field)) != NULL) \TAILQ_NEXT((elm), field)->field.tqe_prev = \(elm)->field.tqe_prev; \else { \(head)->tqh_last = (elm)->field.tqe_prev; \} \*((elm)->field.tqe_prev) = TAILQ_NEXT((elm), field); \
} while (0)
从这个移除节点的操作我们可以看到,这里不需要对链表进行遍历,时间复杂度为O(1);
当next节点不为空时,移除一个节点流程示意图如下:
如果next为空时:
11.遍历链表所有节点(只能读)
#define TAILQ_FOREACH(var, head, field) /* 遍历链表,var接收节点地址 */for ((var) = TAILQ_FIRST((head)); \(var); \(var) = TAILQ_NEXT((var), field))
var: 当前节点的指针head: 链表头指针field: 节点中链接字段的名称(如entries)
如果在遍历过程中删除或修改当前节点(var),后续的 TAILQ_NEXT 操作会访问无效指针,导致未定义行为(如崩溃或数据损坏)。
12.安全的遍历链表节点
为了防止出现遍历过程中删除或修改节点(var)引发的问题,需要使用一个 tvar 变量保存下一个节点的地址。
#define TAILQ_FOREACH_SAFE(var, head, field, tvar) \for ((var) = TAILQ_FIRST((head)); \(var) && ((tvar) = TAILQ_NEXT((var), field), 1); \(var) = (tvar))
var:当前节点的指针head:链表头指针field:节点中链接字段的名称tvar:临时变量,用于保存下一个节点的指针
安全性:在每次迭代前,tvar 会提前保存下一个节点的指针。即使当前节点(var)被删除,tvar 仍然有效,可以继续遍历。
(var) && ((tvar) = TAILQ_NEXT((var), field), 1);
这一个语句中,继续遍历的条件时,var不为NULL;每次判断时,就把下一个节点的地址保存到tvar中。
((tvar) = TAILQ_NEXT(var, field), 1)
这段代码包含两个关键部分:
1.先执行(tvar) = TAILQ_NEXT(var, field) 语句,tvar变量保存下一个节点地址。
2.逗号操作符 ,:在 C 语言中,逗号操作符会按顺序执行其左右两边的表达式,并返回最后一个表达式的结果。
- 例如:
(b = 2, 3)的最终b的值为3。
强制返回值 1:无论左侧表达式的结果如何,逗号操作符右侧的 1 会作为整个表达式的最终值。((tvar) = TAILQ_NEXT(var, field), 1) 整个表达式,值恒为1。
其他的函数
- 倒序遍历所有节点
#define TAILQ_FOREACH_REVERSE(var, head, headname, field) \for ((var) = TAILQ_LAST((head), headname); \(var); \(var) = TAILQ_PREV((var), headname, field))
- 安全的倒序遍历所有节点
#define TAILQ_FOREACH_REVERSE_SAFE(var, head, headname, field, tvar) \for ((var) = TAILQ_LAST((head), headname); \(var) && ((tvar) = TAILQ_PREV((var), headname, field), 1); \(var) = (tvar))
- 在链表的某个已知节点(
listelm)之后插入新节点(elm)
#define TAILQ_INSERT_AFTER(head, listelm, elm, field)
- 在链表的某个已知节点(
listelm)之前插入新节点(elm)
#define TAILQ_INSERT_BEFORE(listelm, elm, field)
四、TAILQ的使用
测试例程:
#include <stdio.h>
#include <stdlib.h>
#include <sys/queue.h>/* 定义tailq 节点结构体 */
struct tailq_node{int val;TAILQ_ENTRY(tailq_node) entries;
};/* 链表头声明 */
TAILQ_HEAD(tailq_head, tailq_node);int main(void) {printf("tailq example\n");struct tailq_head head;/* 队列头的初始化 */TAILQ_INIT(&head);/* 插入节点 node 1 (val = 3)*/struct tailq_node* node1 = malloc(sizeof(struct tailq_node));node1->val = 3;TAILQ_INSERT_HEAD(&head, node1, entries);/* 插入节点 node 2 (val = 9) */struct tailq_node* node2 = malloc(sizeof(struct tailq_node));node2->val = 9;TAILQ_INSERT_TAIL(&head, node2, entries);/* 插入节点 node 3 (val = 17) */struct tailq_node* node3 = malloc(sizeof(struct tailq_node));node3->val = 98;TAILQ_INSERT_TAIL(&head, node3, entries);/* 打印尾结点数值 */struct tailq_node* tail_node = TAILQ_LAST(&head, tailq_head);printf("tail_first->val = %d \n",tail_node->val);/* 只读遍历所有节点 */struct tailq_node *temp = NULL;printf("travel list:");TAILQ_FOREACH(temp, &head, entries){printf("%d, ",temp->val);}printf("\n");printf("remove node 1\n");TAILQ_REMOVE(&head, node1, entries);printf("travel list:");TAILQ_FOREACH(temp, &head, entries){printf("%d, ",temp->val);}return 0;
}
输出:
tailq example
tail_first->val = 98
travel list:3, 9, 98,
remove node 1
travel list:9, 98,
以上就是TAILQ的双向有尾巴链表的使用。