域名备案查询系统官网/seo是什么学校
目的:为了让大模型的输出更贴合人类的偏好,拟合有用真实无害的结果。
RLHF(Reinforcement Learning fromHuman Feedback,人类反馈强化学习)
思维导图
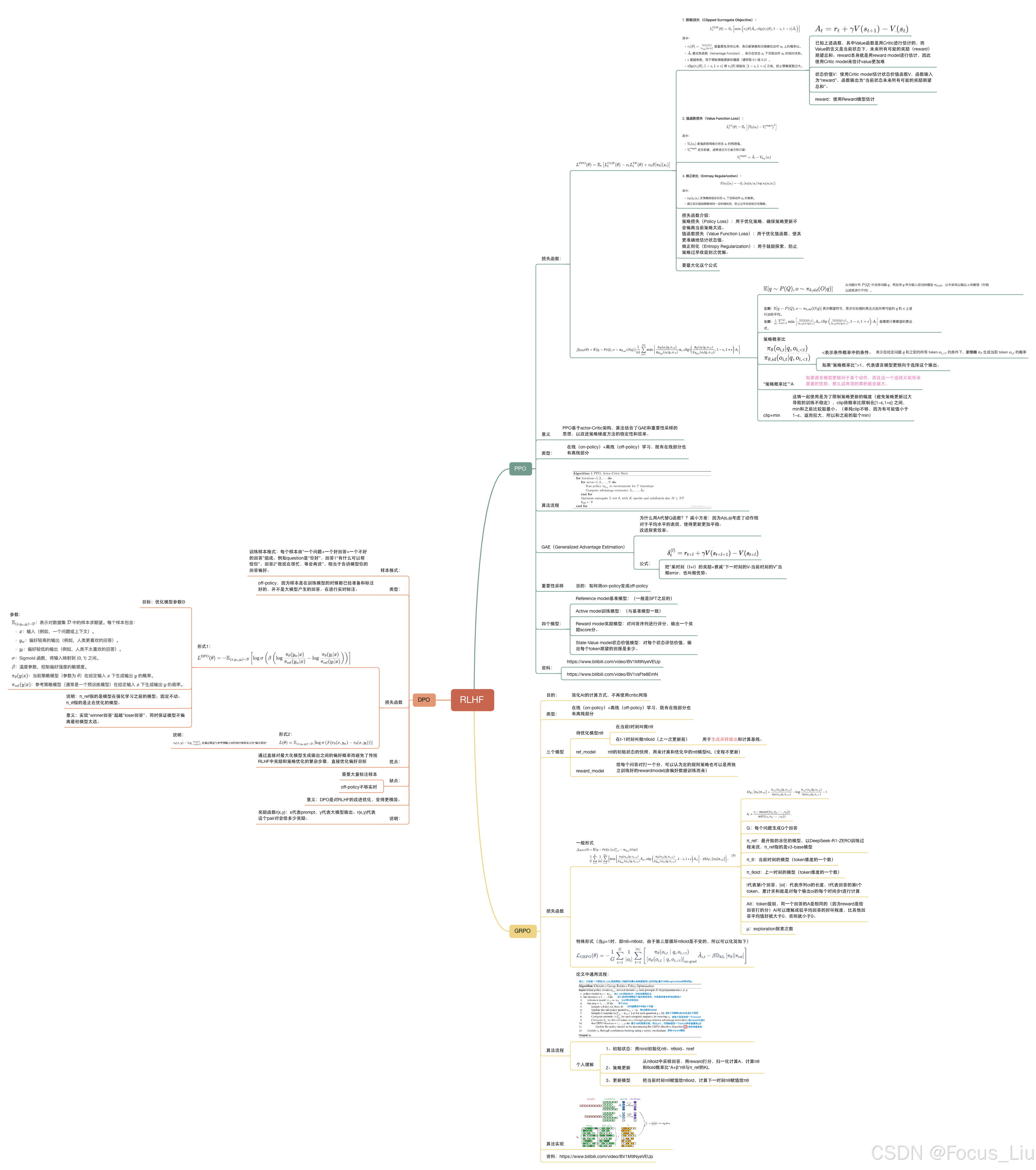
技术路线
发布时间:之前是采用PPO,但是最近采用DPO,现在使用的是GRPO(和PPO很像)。

- SFT 可以单独使用,但效果通常不如 RLHF/DPO 好。
- RLHF = SFT + 强化学习(PPO),适用于复杂任务,但计算开销大。
- DPO = SFT + 直接优化,无需强化学习,计算更简单,但效果接近 RLHF。
背景知识
on-policy与off-policy区别
①宽泛理解
On-Policy(一边学一遍执行任务):这就像一个人一边学习一边执行任务。你在执行任务的同时,也在尝试改进你当前正在使用的方法。如果你发现了一个更好的方法,你会立即尝试在下一次任务中使用它。这种方法更像是“试错”的过程,你不断地改进自己的策略,但你的学习和执行是紧密相关的。
Off-Policy(先学习任务样例,再执行):这就像你在一边学习,一边观察其他人如何执行任务,然后在自己执行任务时应用你所学到的。你可以从其他人的经验中学习,而不必亲自尝试每个可能的方法。这种方法更加灵活,你可以在学习过程中积累经验,然后在以后的任务中应用这些经验,即使你的策略发生了变化。
-
On-Policy 方法严格依赖当前策略生成的数据,数据效率较低,但训练过程更稳定。
-
Off-Policy 方法可以利用历史数据,数据效率更高,但可能需要额外的技巧(如目标网络)来稳定训练。
翻遍整个B站!这绝对是2023年讲的最好的强化学习零基础入门到精通完整版教程(含实战源码)_哔哩哔哩_bilibili
②从采样的时间线来理解
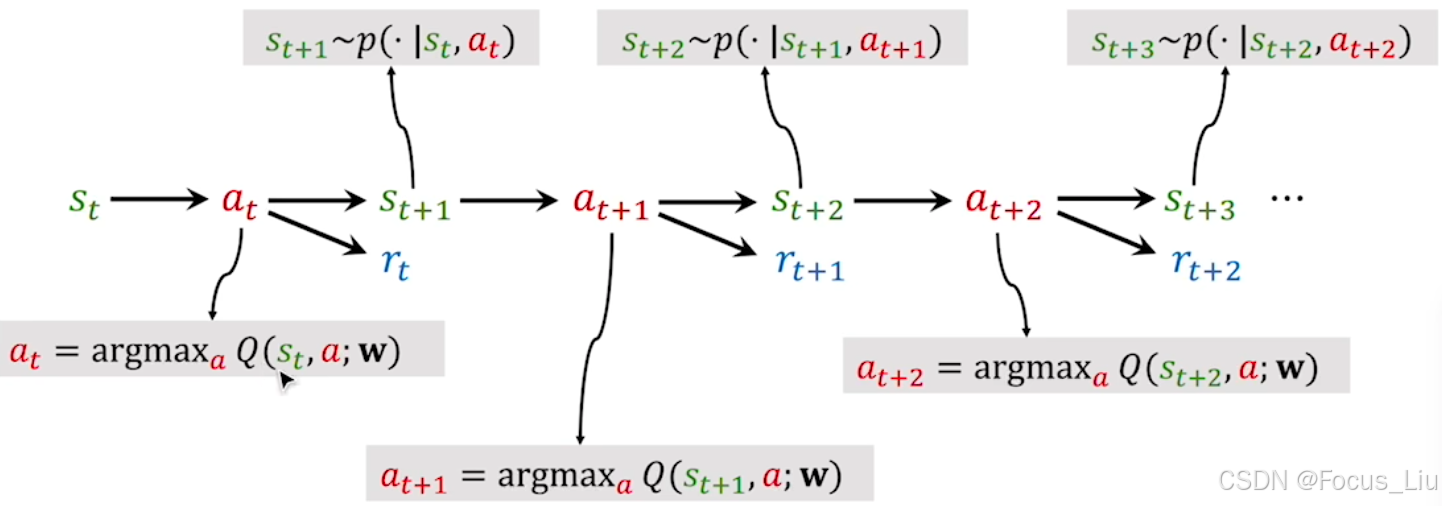
状态s时,我们根据Q函数得到at,执行at得到s(t+1),此时我们会更新Q函数(也就是Q函数中的w),如果下一步动作的a_t+1是始终是根据原始的Q函数计算得出那就是off-policy,如果下一步的动作a_t+1是根据最近一次更新的Q函数计算得出那就是on-policy。(是否是on-policy是看是否用的是最新的Q函数)或者说“使用的策略与实际执行的策略是否相同”
③从实际场景来理解
在强化学习中所用到的样本,是提前一次性生成好(off-policy),还是一边训练模型一边用梯度更新后的模型再产生新样本(on-policy)。
1.蒙特卡洛方法(Monte Carlo,MC)
介绍:指使⽤随机数来解决很多计算问题的⽅法总称。也叫作模拟法、统计试验法。
应用1-用随机打点,统计落在圆内的点数占比来求圆周率。
应用2-求定积分:画一个矩阵,随机打点,统计"函数下方的点数:总点数"来计算积分
2.蒙特卡洛树搜索(MCTS)
介绍:一种用来选出“最优的下一步策略”的算法。
原理:重复多次自博弈,每次选择UCT值最高的策略,进行下一步操作(避免因为执行次数低导致的胜率高胜率高引起的偏差)。最后访问次数最多的节点就是最佳策略节点。
流程:选择子节点->展开子节点->自博弈->记录更新数据。
应用:解决强化学习中的博弈问题
3.UCT:(Upper Confidence Bound Apply to Tree)
介绍:一种树搜索算法,可以解决尝试那些胜率高但是执行度低的策略。
公式:UCT=Q_i/N_i + 常数C*根号(ln(T)/N_i) Q_i是i节点赢的次数,N_i是i节点访问次数,C是常数,而T是总访问次数。
理解:例如统计ctr的场景,uct_ctr=ctr加上一个权重,这个权重是是一个随着全局曝光数减小的一个。最终按照uct_ctr降序起到的作用就是优先“item曝光次数少但是ctr高的item,检验他们是不是真的高质量,如果后面曝光了几次ctr降了,那就减少曝光。如果ctr没降多少那就继续曝光。”。
意义:解决访问次数小时,样本不置信的问题。
应用:item的冷启曝光、蒙特卡洛树搜索。
蒙特卡洛方法,用最粗暴的方式解最难的题_哔哩哔哩_bilibili
4.蒙特卡洛估计
想求所有序列的最优解计算梯度,只有将所有路径都遍历一遍才能计算出来,但是这往往不可能。因此我们采用了从所有可能的路径中抽样n条来计算梯度,从采样的序列中抽样来模拟全局成为蒙特卡洛估计。但是这样计算来的梯度就会存在方差。
PPO(Proximal Policy Optimization)近端策略优化
论文提出了两种损失函数,一种是clip形式损失,一中是KL形式损失。clip形式的损失更好些。
DeepSeek-R1核心算法GRPO讲解-从强化学习0基础->PPO->GRPO_哔哩哔哩_bilibili
概念对齐

DPO(Direct Preference Optimization)直接偏好优化
deepseek R1与kimi1.5 硬核解读_哔哩哔哩_bilibili
GRPO
概述:我有一堆问题,我们使用策略(语言模型)给每个问题生成一些回答,根据回答的在奖励系统中的某些奖励,我们应该训练语言模型,使其更偏向于那些高奖励的行为。
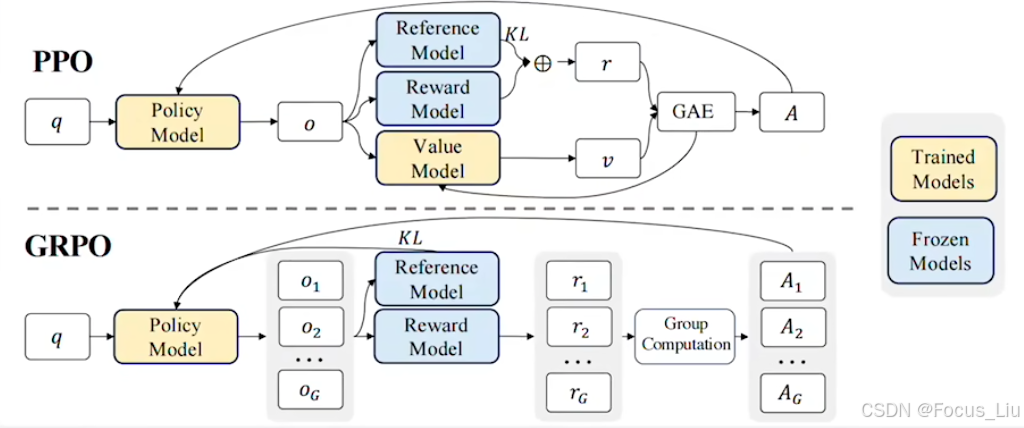
算法流程

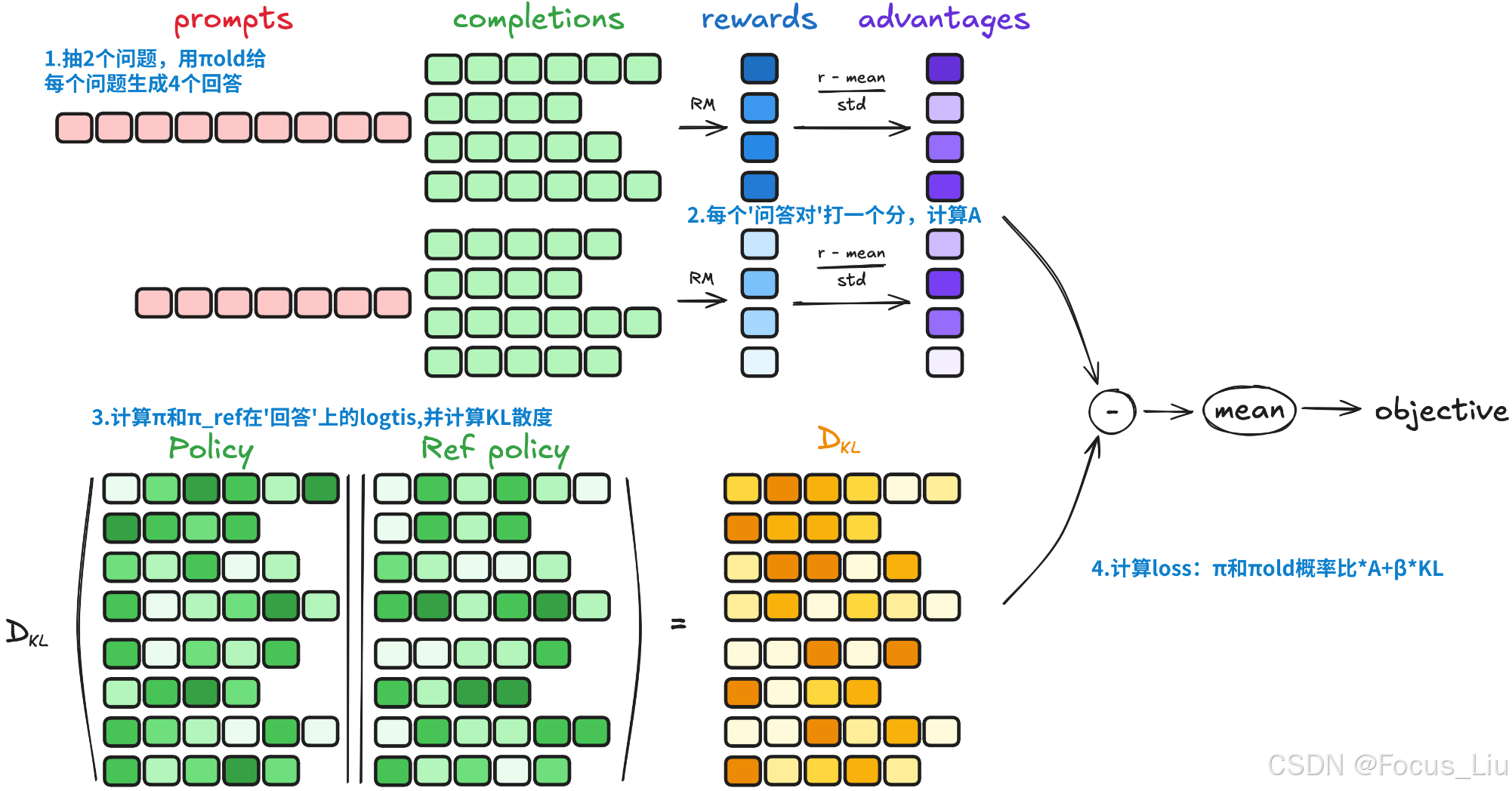
源码实现-trl0.15.2
-
_prepare_inputs(train每次调用_prepare_inputs获取输入,_prepare_inputs根据情况决定是否调用_generate_and_score_completions)
def _prepare_inputs(self, inputs: dict[str, Union[torch.Tensor, Any]]) -> dict[str, Union[torch.Tensor, Any]]:mode = "eval" if self.control.should_evaluate else "train"if mode == "train": #缓存中有 old_per_token_logps、ref_per_token_logps 等信息if self.state.global_step % self.num_iterations == 0: # 当num_iterations=1的时候,只写不读缓存inputs = self._generate_and_score_completions(inputs)self._buffered_inputs[self._step % self.args.gradient_accumulation_steps] = inputs else: # 当num_iterations>1的时候,第一个迭代先写缓存,后续2,3,4..都读缓存,因为同一句prompt的后续的π_old和π_ref都和第一次迭代相同。inputs = self._buffered_inputs[self._step % self.args.gradient_accumulation_steps]self._step += 1else:# In evaluation, we don't reuse completions across multiple updates, so we don't need to buffer inputs.inputs = self._generate_and_score_completions(inputs)return inputs-
_generate_and_score_completions(计算loss前的准备)
def _generate_and_score_completions(self, inputs: dict[str, Union[torch.Tensor, Any]]) -> dict[str, Union[torch.Tensor, Any]]:device = self.accelerator.deviceprompts = [x["prompt"] for x in inputs] #4个相同问题prompts_text = [maybe_apply_chat_template(example, self.processing_class)["prompt"] for example in inputs]prompt_inputs = self.processing_class( #使用tokenizer类,编码,产出input_ids和attention_maskprompts_text, return_tensors="pt", padding=True, padding_side="left", add_special_tokens=False)prompt_inputs = super()._prepare_inputs(prompt_inputs)prompt_ids, prompt_mask = prompt_inputs["input_ids"], prompt_inputs["attention_mask"]if self.max_prompt_length is not None:prompt_ids = prompt_ids[:, -self.max_prompt_length :]prompt_mask = prompt_mask[:, -self.max_prompt_length :]# Generate completions using either vLLM or regular generationif self.args.use_vllm:# 如果使用vllm进行推理加速else:# 普通的推理方式# Regular generation pathwith unwrap_model_for_generation(self.model_wrapped, self.accelerator) as unwrapped_model: # self.model_wrapped 是输入模型增加了lora r=8prompt_completion_ids = unwrapped_model.generate( # 使用self.model_wrapped,对问题生成batch_size个回答,每个回答不一样prompt_ids, attention_mask=prompt_mask, generation_config=self.generation_config )# prompt_completion_ids中包含原有的问题和新增的回答,所以进行切分。得到回答。# Compute prompt length and extract completion idsprompt_length = prompt_ids.size(1)prompt_ids = prompt_completion_ids[:, :prompt_length]completion_ids = prompt_completion_ids[:, prompt_length:]# Mask everything after the first EOS token 计算eos后的为maskis_eos = completion_ids == self.processing_class.eos_token_ideos_idx = torch.full((is_eos.size(0),), is_eos.size(1), dtype=torch.long, device=device)eos_idx[is_eos.any(dim=1)] = is_eos.int().argmax(dim=1)[is_eos.any(dim=1)]sequence_indices = torch.arange(is_eos.size(1), device=device).expand(is_eos.size(0), -1)completion_mask = (sequence_indices <= eos_idx.unsqueeze(1)).int()# Concatenate prompt_mask with completion_mask for logit computationattention_mask = torch.cat([prompt_mask, completion_mask], dim=1) # (B, P+C) #合并问题和回答的masklogits_to_keep = completion_ids.size(1) # we only need to compute the logits for the completion tokenswith torch.no_grad():# When using num_iterations == 1, old_per_token_logps == per_token_logps, so we can skip it's# computation here, and use per_token_logps.detach() instead.if self.num_iterations > 1:old_per_token_logps = self._get_per_token_logps(self.model, prompt_completion_ids, attention_mask, logits_to_keep)else:old_per_token_logps = Noneif self.beta == 0.0:ref_per_token_logps = Noneelif self.ref_model is not None: ref_per_token_logps = self._get_per_token_logps(self.ref_model, prompt_completion_ids, attention_mask, logits_to_keep)else: #ref_model可以单独配,如果不配置,就用关闭self.model关闭lora权重来预测with self.accelerator.unwrap_model(self.model).disable_adapter():ref_per_token_logps = self._get_per_token_logps(self.model, prompt_completion_ids, attention_mask, logits_to_keep)# Decode the generated completionscompletions_text = self.processing_class.batch_decode(completion_ids, skip_special_tokens=True)if is_conversational(inputs[0]):#输入是否是对话类型的(list类型)completions = []for prompt, completion in zip(prompts, completions_text):bootstrap = prompt.pop()["content"] if prompt[-1]["role"] == "assistant" else ""completions.append([{"role": "assistant", "content": bootstrap + completion}])else:#输入是上下文格式的completions = completions_textrewards_per_func = torch.zeros(len(prompts), len(self.reward_funcs), device=device)for i, (reward_func, reward_processing_class) in enumerate(zip(self.reward_funcs, self.reward_processing_classes)):if isinstance(reward_func, nn.Module): # Module instead of PretrainedModel for compat with compiled models #reward_model是NN模型reward_func_name = f"reward {reward_func.config._name_or_path.split('/')[-1]}"else: #reward_func是函数、或者其他,甚至http接口都可以reward_func_name = reward_func.__name__with profiling_context(self, reward_func_name): #记录profiling_context中矩阵的耗时if isinstance(reward_func, nn.Module): # Module instead of PretrainedModel for compat with compiled modelsif is_conversational(inputs[0]):messages = [{"messages": p + c} for p, c in zip(prompts, completions)]texts = [apply_chat_template(x, reward_processing_class)["text"] for x in messages]else:texts = [p + c for p, c in zip(prompts, completions)] #原始 问答文本reward_inputs = reward_processing_class(texts, return_tensors="pt", padding=True, padding_side="right", add_special_tokens=False)reward_inputs = super()._prepare_inputs(reward_inputs) # 编码后input_ids和attention_maskwith torch.inference_mode():rewards_per_func[:, i] = reward_func(**reward_inputs).logits[:, 0] # Shape (B*G,) 输出[4, 1] 应该是batch_size*group batch_zide是回答数 group是问题数else:# Repeat all input columns (but "prompt" and "completion") to match the number of generationskeys = [key for key in inputs[0] if key not in ["prompt", "completion"]]reward_kwargs = {key: [example[key] for example in inputs] for key in keys}output_reward_func = reward_func(prompts=prompts, completions=completions, **reward_kwargs)rewards_per_func[:, i] = torch.tensor(output_reward_func, dtype=torch.float32, device=device)# Gather the reward per function: this part is crucial, because the rewards are normalized per group and the# completions may be distributed across processesrewards_per_func = gather(rewards_per_func) #适配在多进程或分布式训练环境下: torch.Size([4, 1])# Apply weights to each reward function's output and sumrewards = (rewards_per_func * self.reward_weights.to(device).unsqueeze(0)).sum(dim=1)# Compute grouped-wise rewardsmean_grouped_rewards = rewards.view(-1, self.num_generations).mean(dim=1)std_grouped_rewards = rewards.view(-1, self.num_generations).std(dim=1)# Normalize the rewards to compute the advantagesmean_grouped_rewards = mean_grouped_rewards.repeat_interleave(self.num_generations, dim=0)std_grouped_rewards = std_grouped_rewards.repeat_interleave(self.num_generations, dim=0)advantages = (rewards - mean_grouped_rewards) / (std_grouped_rewards + 1e-4) #减均值除方差 从reward得到advantage# Slice to keep only the local part of the dataprocess_slice = slice(self.accelerator.process_index * len(prompts),(self.accelerator.process_index + 1) * len(prompts),)advantages = advantages[process_slice]# Log the metricsmode = "eval" if self.control.should_evaluate else "train"completion_length = self.accelerator.gather_for_metrics(completion_mask.sum(1)).float().mean().item()self._metrics[mode]["completion_length"].append(completion_length)reward_per_func = rewards_per_func.mean(0)for i, reward_func in enumerate(self.reward_funcs):if isinstance(reward_func, nn.Module): # Module instead of PretrainedModel for compat with compiled modelsreward_func_name = reward_func.config._name_or_path.split("/")[-1]else:reward_func_name = reward_func.__name__self._metrics[mode][f"rewards/{reward_func_name}"].append(reward_per_func[i].item())self._metrics[mode]["reward"].append(rewards.mean().item())self._metrics[mode]["reward_std"].append(std_grouped_rewards.mean().item())if self.log_completions and self.state.global_step % self.args.logging_steps == 0:prompts_to_log = gather_object(prompts_text)completions_to_log = gather_object(completions_text)rewards_to_log = rewards.tolist()if self.accelerator.is_main_process:if is_rich_available():print_prompt_completions_sample(prompts_to_log,completions_to_log,rewards_to_log,self.state.global_step,)if self.args.report_to and "wandb" in self.args.report_to and wandb.run is not None:import pandas as pd# For loggingtable = {"step": [str(self.state.global_step)] * len(rewards),"prompt": prompts_to_log,"completion": completions_to_log,"reward": rewards.tolist(),}df = pd.DataFrame(table)wandb.log({"completions": wandb.Table(dataframe=df)})return {"prompt_ids": prompt_ids,"prompt_mask": prompt_mask,"completion_ids": completion_ids,"completion_mask": completion_mask,"old_per_token_logps": old_per_token_logps,"ref_per_token_logps": ref_per_token_logps,"advantages": advantages,}
-
compute_loss
@profiling_decoratordef compute_loss(self, model, inputs, return_outputs=False, num_items_in_batch=None): # 每个question都会调用一次compute_lossif return_outputs:raise ValueError("The GRPOTrainer does not support returning outputs")# Compute the per-token log probabilities for the modelprompt_ids, prompt_mask = inputs["prompt_ids"], inputs["prompt_mask"] # prompt_ids 是[4, 395],每行都相同,把一个question复制了成4行completion_ids, completion_mask = inputs["completion_ids"], inputs["completion_mask"] # completion_ids 是[4, 128],1个问题生成4个回答input_ids = torch.cat([prompt_ids, completion_ids], dim=1) #合并 问题-回答attention_mask = torch.cat([prompt_mask, completion_mask], dim=1)logits_to_keep = completion_ids.size(1) # we only need to compute the logits for the completion tokensper_token_logps = self._get_per_token_logps(model, input_ids, attention_mask, logits_to_keep) # 计算回答序列上每个词,在model上的log概率# Compute the KL divergence between the model and the reference modelif self.beta != 0.0:ref_per_token_logps = inputs["ref_per_token_logps"] #计算回答序列上每个词,在ref_model上的log概率 ,ref_per_token_logps与per_token_logps计算KL散度per_token_kl = ( #shape不变[4, 128]torch.exp(ref_per_token_logps - per_token_logps) - (ref_per_token_logps - per_token_logps) - 1)# Compute the lossadvantages = inputs["advantages"] # [4],也就是优势是回答维度的,值有正有负# When using num_iterations == 1, old_per_token_logps == per_token_logps, so we can skip it's computation (see# _generate_and_score_completions) and use per_token_logps.detach() instead.old_per_token_logps = inputs["old_per_token_logps"] if self.num_iterations > 1 else per_token_logps.detach() #第一个epoch, inputs["old_per_token_logps"]都是nonecoef_1 = torch.exp(per_token_logps - old_per_token_logps) # πΘ 与πΘold 计算策略概率比(先logit相减再exp) [4, 128]coef_2 = torch.clamp(coef_1, 1 - self.epsilon, 1 + self.epsilon)per_token_loss1 = coef_1 * advantages.unsqueeze(1) # 乘优势 [4, 128]per_token_loss2 = coef_2 * advantages.unsqueeze(1)per_token_loss = -torch.min(per_token_loss1, per_token_loss2) #裁剪和不裁剪取最小if self.beta != 0.0:per_token_loss = per_token_loss + self.beta * per_token_kl #求和loss = (per_token_loss * completion_mask).sum() / completion_mask.sum() #token维度求和# Log the metricsmode = "eval" if self.control.should_evaluate else "train"if self.beta != 0.0:mean_kl = ((per_token_kl * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean()self._metrics[mode]["kl"].append(self.accelerator.gather_for_metrics(mean_kl).mean().item())is_clipped = (per_token_loss1 < per_token_loss2).float()clip_ratio = (is_clipped * completion_mask).sum() / completion_mask.sum() #记录有多少触发的clip的占比self._metrics[mode]["clip_ratio"].append(self.accelerator.gather_for_metrics(clip_ratio).mean().item())return loss并行训练参数:
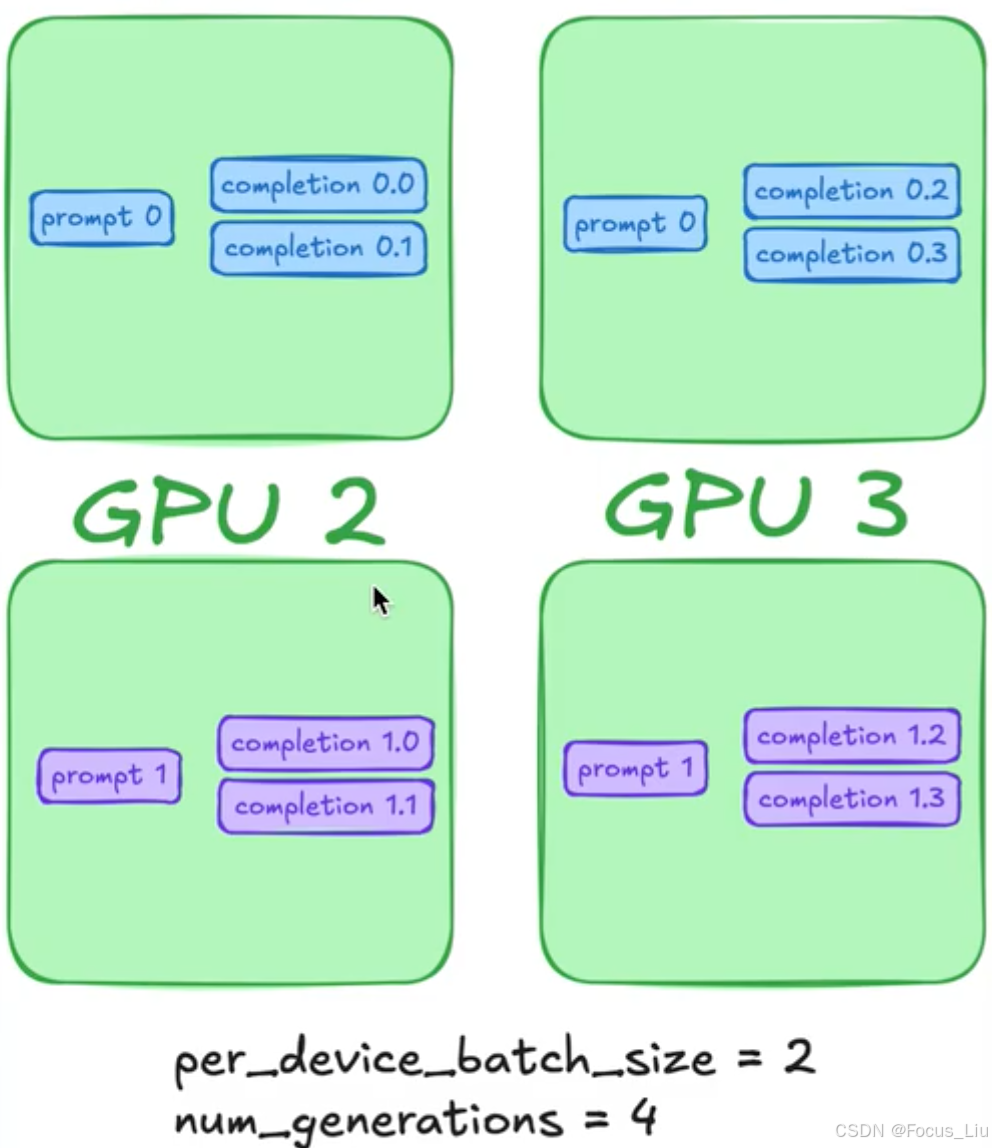
- 数据集在加载的时候就根据total_cnt,给每个question生成了下标,然后按照重复次数和gpu处理个数进行分组,也就是知道了哪个gpu要处理哪些下标。
总结:
如果一个模型要进行GRPO强化,只需要准备一个reward模型或者策略就行了+一些question即可。
策略概率比的实现:
coef_1 = torch.exp(per_token_logps - old_per_token_logps) # πΘ与πΘold 计算策略概率比 [4, 128]
因为![]() ,per_token_logs和old_per_token_logps都是softmax再取log后得到的,每个元素都是负数,现在相减再e的对数,也就是原来的值相除,对应公式中
,per_token_logs和old_per_token_logps都是softmax再取log后得到的,每个元素都是负数,现在相减再e的对数,也就是原来的值相除,对应公式中![]() 。
。
- 变量中logps全称应该是log-probabilities,也就是对数概率,它是先softmax再取log对数。
其他
- v3的时候,rewardmodel还是一个Learn出来的模型,到r1的时候就已经是一套规则了。
- PPO需要4个模型,训练时需要可以使用1个大模型4套Lora来实现。
- GRPO没有使用MCTS(蒙特卡洛搜索树):句子生层的空间太大,难训练练好的Critic模型估计Value。
- 使用蒙特卡洛搜索树可以不用穷举全部的轨迹可能就能优化loss函数,但是问题是可能会与最优路径产生方差。
- 为什么要增加一个和ref模型的KL散度?例如我们想让模型变得更有礼貌,让回答的话术更有温柔,如果不限制KL散度,模型可能就投机取巧,在之前的基础上增加多个“谢谢”也能满足你的要求,但是这时候的结构不是你想要的。
- 【Reward Hacking】:指的是在强化学习中,智能体利用奖励函数中的漏洞或缺陷,通过采取意料之外但能最大化奖励的行为,从而偏离预期目标。这种现象反映了奖励设计的不完善,使得智能体获得高奖励的同时,并未真正完成任务意图。(就是你loss函数不合理,然后模型确实实现loss最小化,但是并不是你想要的效果)
- 优势项A的通俗理解:选择输出这个token比输出其他token要好多少。
- PPO是基于结果的奖励,让后将优势项分配到之前所有的token上。
- R1论文中尝试了过程奖励,但是没有成功(将问题划分成步骤是困难的;有的中间结果好不好只有最后才知道)
- 使用蒙特卡洛搜索树得到的结果不如通过强化学习驱动的效果。
- 重要性采样:复用旧策略的样本来估计新策略的优化方向。
DPO损失函数和GRPO的区别
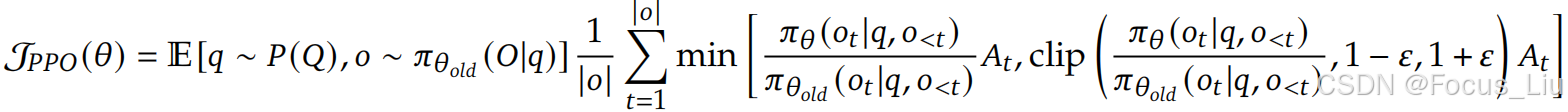

- PPO是一个问答对就能计算出一个loss,GRPO是必须一个问题的一组回答计算一个损失。
- GRPO多了KL损失项目
- KL散度不是新增了,而是从之前的A中提到外面来,简化了A的计算。
[LLM+RL] 理解 GRPO 公式原理及 TRL GrpoTrainer 代码实现(advantage 与 loss 计算)_哔哩哔哩_bilibili