做网站编辑的感受/搜狗站长推送工具
综合案例
- 将MNIST数据集保存成本地图片
- 读取本地图片进行训练
- 读取自己的数据集进行训练
- 用自己的模型进行训练
- 获得更多评价指标
- 提升模型性能的方法
MNIST转本地图片
import os
import torchvision
import torchvision.transforms as transforms# 下载MNIST数据集
transform = transforms.Compose([transforms.ToTensor()])
mnist_trainset = torchvision.datasets.MNIST(root='./data', train=True,download=True, transform=transform)
mnist_testset = torchvision.datasets.MNIST(root='./data', train=False,download=True, transform=transform)# 创建一个目录来保存图像(如果它还不存在)
os.makedirs('./mnist_images/train', exist_ok=True)
os.makedirs('./mnist_images/test', exist_ok=True)# 遍历数据集并保存图像
for idx, (image, label) in enumerate(mnist_trainset):# 创建类别文件夹(如果它还不存在)label_dir = os.path.join('./mnist_images/train', str(label))os.makedirs(label_dir, exist_ok=True)# 转换为PIL图像并保存pil_image = transforms.ToPILImage()(image)pil_image.save(os.path.join(label_dir, f'{idx}.jpg'))# 遍历数据集并保存图像
for idx, (image, label) in enumerate(mnist_testset):# 创建类别文件夹(如果它还不存在)label_dir = os.path.join('./mnist_images/test', str(label))os.makedirs(label_dir, exist_ok=True)# 转换为PIL图像并保存pil_image = transforms.ToPILImage()(image)pil_image.save(os.path.join(label_dir, f'{idx}.jpg'))# 打印完成消息
print("All images have been saved successfully.")
接下来我来讲解一下上述的代码,在我的视角看来应该要将的东西
transform = transforms.Compose([transforms.ToTensor()])
使用 torchvision.transforms 模块中的 Compose 和 ToTensor 方法来定义一个图像预处理的转换操作,主要用于将图像数据转换为 PyTorch 张量(Tensor),以便用于深度学习模型的训练或推理。
mnist_trainset=torchvision.datasets.MNIST(root='./data',train=True,download=True, transform=transform
自动下载MNIST数据集,然后将其转换为tensor格式
os.makedirs('./mnist_images/train', exist_ok=True)
使用 Python 的 os 模块中的 makedirs 函数来创建目录。具体来说,它的作用是创建一个目录路径 ./mnist_images/train,并且如果该目录已经存在,不会报错。
其中exist_ok=True,在目录已经存在的情况下,不会报错
label_dir = os.path.join('./mnist_images/train', str(label))
这一句代码的作用就是,把'./mnist_images/train'字符串和str(label)字符串拼接起来。
pil_image = transforms.ToPILImage()(image)
这行代码的作用是将输入的图像数据(通常是 PyTorch 张量或 NumPy 数组)转换为 PIL 图像对象。

读取本地图片进行训练
import os
import torch
from torch.utils.data import Dataset, DataLoader
import cv2 as cvclass MNISTDataset(Dataset):def __init__(self, root_dir):self.root_dir = root_dirself.file_list = []self.name_list = []self.id_list = []for root, dirs, files in os.walk(self.root_dir):if dirs:self.name_list = dirsfor file_i in files:file_i_full_path = os.path.join(root, file_i)file_class = os.path.split(file_i_full_path)[0].split('\\')[-1]self.id_list.append(self.name_list.index(file_class))self.file_list.append(file_i_full_path)def __len__(self):return len(self.file_list)def __getitem__(self, idx):img = self.file_list[idx]img = cv.imread(img, 0)img = cv.resize(img, dsize=(28, 28))img = torch.from_numpy(img).float()label = self.id_list[idx]# print(label)label = torch.tensor(label)return img, labelif __name__ == '__main__':my_dataset_train = MNISTDataset(r'mnist_images/train')my_dataloader_train = DataLoader(my_dataset_train, batch_size=10, shuffle=True)# 尝试读取训练集数据print("读取训练集数据")for x, y in my_dataloader_train:print(x.type(), x.shape, y)my_dataset_test = MNISTDataset(r'mnist_images/test')my_dataloader_test = DataLoader(my_dataset_test, batch_size=10, shuffle=False)# 尝试读取训练集数据print("读取测试集数据")for x, y in my_dataloader_test:print(x.shape, y)
在前面讲了,Dataset的三件套,__init__,__len__,__getitem__如果这三个魔法方法忘记了,可以回去看看以前的文章。
for root, dirs, files in os.walk(self.root_dir):
Python 中使用 os.walk 函数的一个典型用法,用于遍历指定目录及其所有子目录中的文件和文件夹。
-
root:当前正在遍历的目录路径。 -
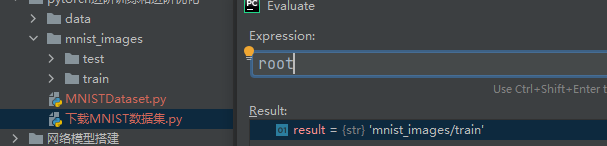
-
dirs:当前目录下的子目录列表。 -
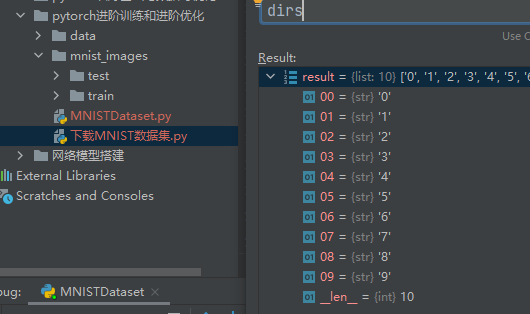
-
files:当前目录下的文件列表 -
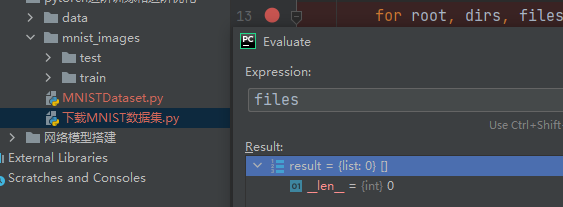
self.name_list
列表当中存的就是,标签名字
进入第二次循环后
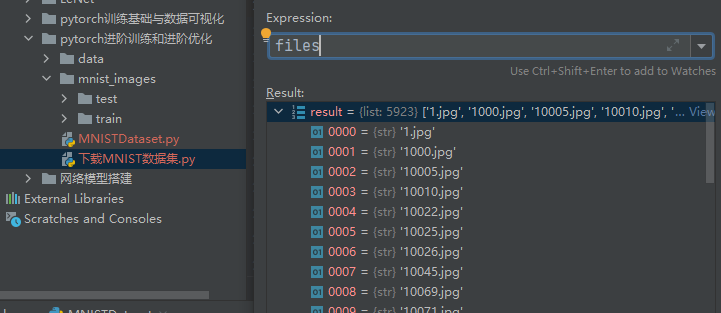
os.path.split(file_i_full_path)[0]
将 file_i_full_path 分割为目录部分和文件名部分,返回一个元组 (head, tail)

self.name_list.index(file_class)
在 self.name_list 列表中查找 file_class 元素的索引位置。
self.file_list最后的效果

self.name_list最后的效果

self.id_list最后的效果

MyModel
import torch
from torch import nn
from torchsummary import summary# 定义模型
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28 * 28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10))def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsif __name__ == '__main__':model = NeuralNetwork()print(model)summary(model, (1,28,28))
self.flatten = nn.Flatten()
通常用于深度学习模型中,特别是在卷积神经网络(CNN)和全连接网络(FCN)之间进行数据转换时。它的作用是将多维张量(Tensor)“展平”为一维张量。
summary(model, (1, 28, 28))
打印模型的结构和参数信息,帮助开发者快速了解模型的每一层的详细信息、输入输出形状、参数数量等。

main函数
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
from tqdm import tqdm # pip install tqdm
import matplotlib.pyplot as plt
import os
from torchsummary import summaryfrom torch.utils.tensorboard import SummaryWriterimport wandb
import datetimefrom MyModel import NeuralNetwork
from MnistDataset import MNISTDataset# # 定义训练函数
def train(dataloader, model, loss_fn, optimizer):# 初始化训练数据集的大小和批次数量size = len(dataloader.dataset)num_batches = len(dataloader)# 设置模型为训练模式model.train()# 初始化总损失和正确预测数量loss_total = 0correct = 0# 遍历数据加载器中的所有数据批次for X, y in tqdm(dataloader):# 将数据和标签移动到指定设备(例如GPU)X, y = X.to(device), y.to(device)# 使用模型进行预测pred = model(X)# 计算正确预测的数量correct += (pred.argmax(1) == y).type(torch.float).sum().item()# 计算预测结果和真实结果之间的损失loss = loss_fn(pred, y)# 累加总损失loss_total += loss.item()# 执行反向传播,计算梯度loss.backward()# 更新模型参数optimizer.step()# 清除梯度信息optimizer.zero_grad()# 计算平均损失和准确率loss_avg = loss_total / num_batchescorrect /= size# 返回准确率和平均损失,保留三位小数return round(correct, 3), round(loss_avg,3)# 定义测试函数
def test(dataloader, model, loss_fn):# 初始化测试数据集的大小和批次数量size = len(dataloader.dataset)num_batches = len(dataloader)# 设置模型为评估模式model.eval()# 初始化测试损失和正确预测数量test_loss, correct = 0, 0# 不计算梯度,以提高计算效率并减少内存使用with torch.no_grad():# 遍历数据加载器中的所有数据批次for X, y in tqdm(dataloader):# 将数据和标签移动到指定设备(例如GPU)X, y = X.to(device), y.to(device)# 使用模型进行预测pred = model(X)# 累加预测损失test_loss += loss_fn(pred, y).item()# 累加正确预测的数量correct += (pred.argmax(1) == y).type(torch.float).sum().item()# 计算平均测试损失和准确率test_loss /= num_batchescorrect /= size# 返回准确率和平均测试损失,保留三位小数return round(correct, 3), round(test_loss, 3)def writedata(txt_log_name, tensorboard_writer, epoch, train_accuracy, train_loss, test_accuracy, test_loss):# 保存到文档with open(txt_log_name, "a+") as f:f.write(f"Epoch:{epoch}\ttrain_accuracy:{train_accuracy}\ttrain_loss:{train_loss}\ttest_accuracy:{test_accuracy}\ttest_loss:{test_loss}\n")# 保存到tensorboard# 记录全连接层参数for name, param in model.named_parameters():if 'linear' in name:tensorboard_writer.add_histogram(name, param.clone().cpu().data.numpy(), global_step=epoch)tensorboard_writer.add_scalar('Accuracy/train', train_accuracy, epoch)tensorboard_writer.add_scalar('Loss/train', train_loss, epoch)tensorboard_writer.add_scalar('Accuracy/test', test_accuracy, epoch)tensorboard_writer.add_scalar('Loss/test', test_loss, epoch)wandb.log({"Accuracy/train": train_accuracy,"Loss/train": train_loss,"Accuracy/test": test_accuracy,"Loss/test": test_loss})def plot_txt(log_txt_loc):with open(log_txt_loc, 'r') as f:log_data = f.read()# 解析日志数据epochs = []train_accuracies = []train_losses = []test_accuracies = []test_losses = []for line in log_data.strip().split('\n'):epoch, train_acc, train_loss, test_acc, test_loss = line.split('\t')epochs.append(int(epoch.split(':')[1]))train_accuracies.append(float(train_acc.split(':')[1]))train_losses.append(float(train_loss.split(':')[1]))test_accuracies.append(float(test_acc.split(':')[1]))test_losses.append(float(test_loss.split(':')[1]))# 创建折线图plt.figure(figsize=(10, 5))# 训练数据plt.subplot(1, 2, 1)plt.plot(epochs, train_accuracies, label='Train Accuracy')plt.plot(epochs, test_accuracies, label='Test Accuracy')plt.title('Training Metrics')plt.xlabel('Epoch')plt.ylabel('Value')plt.legend()# 设置横坐标刻度为整数plt.xticks(range(min(epochs), max(epochs) + 1))# 测试数据plt.subplot(1, 2, 2)plt.plot(epochs, train_losses, label='Train Loss')plt.plot(epochs, test_losses, label='Test Loss')plt.title('Testing Metrics')plt.xlabel('Epoch')plt.ylabel('Value')plt.legend()# 设置横坐标刻度为整数plt.xticks(range(min(epochs), max(epochs) + 1))plt.tight_layout()plt.show()if __name__ == '__main__':batch_size = 64init_lr = 1e-3epochs = 5log_root = "logs"log_txt_loc = os.path.join(log_root,"log.txt")# 指定TensorBoard数据的保存地址tensorboard_writer = SummaryWriter(log_root)# WandB信息保存地址run_time = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")wandb.init(dir=log_root,project='MNIST',name=f"run-{run_time}",config={"learning_rate": init_lr,"batch_size": batch_size,"model": "NeuralNetwork","dataset": "MNIST","epochs": epochs,})if os.path.isdir(log_root):passelse:os.mkdir(log_root)train_data = MNISTDataset(r'mnist_images/train')test_data = MNISTDataset(r'mnist_images/test')# 创建数据加载器train_dataloader = DataLoader(train_data, batch_size=batch_size)test_dataloader = DataLoader(test_data, batch_size=batch_size)for X, y in test_dataloader:print(f"Shape of X [N, C, H, W]: {X.shape}")print(f"Shape of y: {y.shape} {y.dtype}")break# 指定设备device = "cuda" if torch.cuda.is_available() else "cpu"print(f"Using {device} device")model = NeuralNetwork().to(device)print(model)summary(model, (1,28,28))# 模拟输入,大小和输入相同即可init_img = torch.zeros((1, 1, 28, 28), device=device)tensorboard_writer.add_graph(model, init_img)# 添加wandb的模型记录wandb.watch(model, log='all', log_graph=True)# 定义损失函数loss_fn = nn.CrossEntropyLoss()# 定义优化器optimizer = torch.optim.SGD(model.parameters(), lr=init_lr)best_acc = 0# 定义循环次数,每次循环里面,先训练,再测试for t in range(epochs):print(f"Epoch {t + 1}\n-------------------------------")train_acc, train_loss = train(train_dataloader, model, loss_fn, optimizer)test_acc, test_loss = test(test_dataloader, model, loss_fn)writedata(log_txt_loc, tensorboard_writer,t,train_acc,train_loss,test_acc,test_loss)# 保存最佳模型if test_acc > best_acc:best_acc = test_acctorch.save(model.state_dict(), os.path.join(log_root,"best.pth"))torch.save(model.state_dict(), os.path.join(log_root,"last.pth"))print("Done!")tensorboard_writer.close()wandb.finish()plot_txt(log_txt_loc)