怎样用linux做网站/百度手机助手下载安卓版
论文地址:https://github.com/hustvl/VAD
代码地址:https://arxiv.org/pdf/2303.12077
1. 摘要
自动驾驶需要对周围环境进行全面理解,以实现可靠的轨迹规划。以往的方法依赖于密集的栅格化场景表示(如:占据图、语义地图)来进行规划,这种方式计算量大,且缺乏实例级的结构信息。
本文提出了 VAD(Vectorized Autonomous Driving),一种端到端的向量化自动驾驶范式,将驾驶场景建模为完全向量化的表示方式。这一范式具有两大优势:
一方面,VAD 利用向量化的动态目标运动信息与地图元素作为显式的实例级规划约束,从而有效提升了规划的安全性;
另一方面,VAD 摒弃了计算密集的栅格表示和手工设计的后处理步骤,因此比以往端到端方法运行速度更快。
在 nuScenes 数据集上,VAD 实现了当前最优的端到端规划性能,在多个指标上大幅超越现有最优方法。基础模型 VAD-Base 将平均碰撞率降低了 29.0%,运行速度提升了 2.5 倍;而轻量版本 VAD-Tiny 在保持可比规划性能的同时,实现了高达 9.3 倍的推理速度提升。
2. 方法
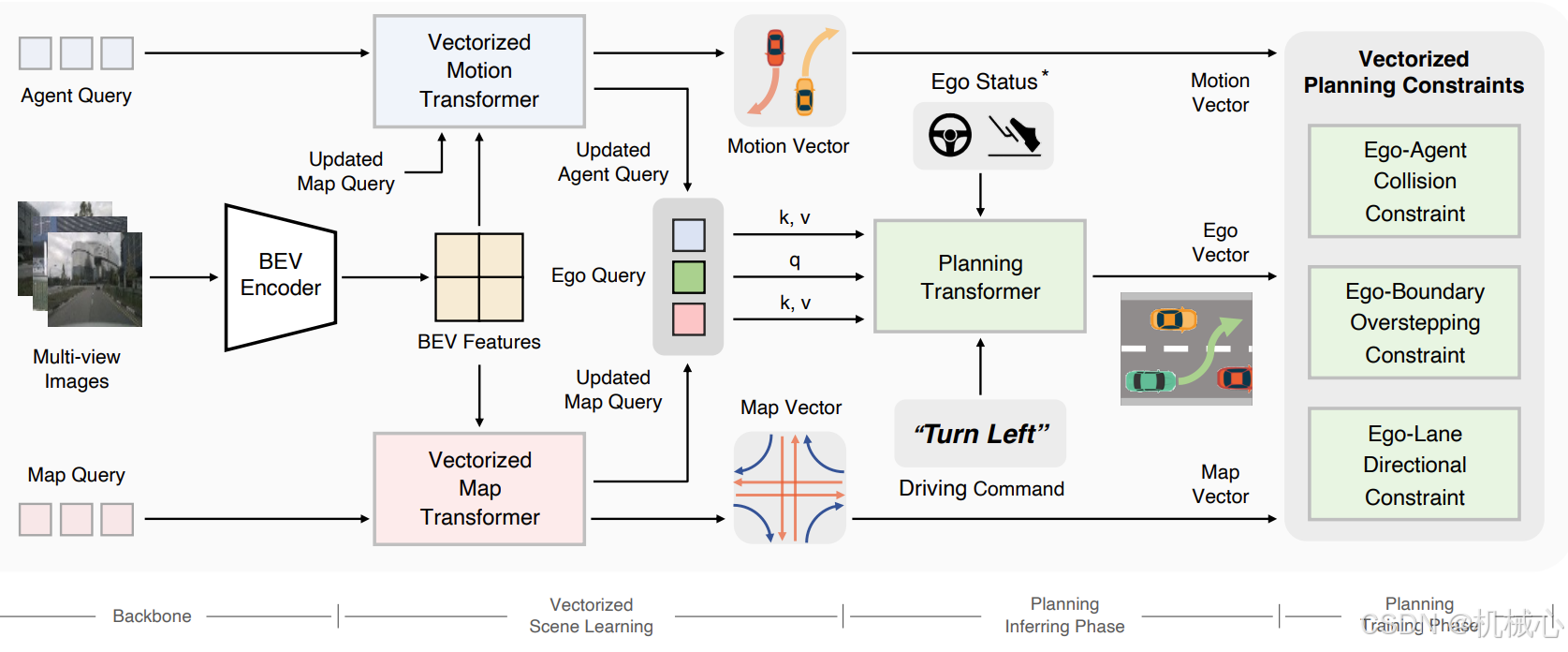
VAD 的整体框架如图 2所示。输入为多帧、多视角的图像,输出为自车未来的规划轨迹。VAD 的框架分为四个阶段:
Backbone:提取图像特征并投影为 BEV(Bird’s-Eye View)特征;
Vectorized Scene Learning:构建向量化的地图与运动表示;
Planning(推理阶段):通过 ego query 与地图/目标交互,生成未来轨迹;
Planning(训练阶段):引入三种向量化约束,对轨迹进行训练正则化。
2.1 向量化场景学习
VAD使用 ResNet50 提取图像特征,经过多层卷积神经网络提取图像的低级和高级特征。使用 BEV Encoder 将图像特征通过空间映射转换为 Bird’s Eye View(BEV)特征图,并使用 Transformer 对其进行进一步的处理,学习图像的全局语义和空间关系。
向量化地图
相比栅格化语义地图,向量化表示能保留更细致的结构信息。论文使用一组 Map Query ,从 BEV 特征中提取地图元素,如:车道线(lane divider)、道路边界(road boundary)以及人行道(pedestrian crossing),每个地图元素表示为 一组点(polyline),并附带类别信息。
是可学习的embedding,类似 DETR 中的 Object Query,维度为100xC(例如100个地图目标),Vecorized Map Transformer使用的是典型的Transformer Decoder结构,先进行self-attention,然后在进行cross-attention,最终输出向量维度为MxD,然后经过地图head可以解析出来就是100x20x2,也就是100个目标,每个目标数据点个数为20个,二维坐标。
向量化交通参与者运动预测
为了高效预测交通参与者(如其他车辆、行人等)的未来轨迹,VAD 使用了一种基于向量化表示的方法来描述它们的运动。这一部分的目标是通过 Agent Queries(交通参与者查询)来学习每个交通参与者的运动特征,并通过 Deformable Attention 机制与环境的 BEV(Bird's-Eye View)特征进行交互,从而预测它们的未来行为。
Agent Queries 是一组表示交通参与者(例如其他车辆、行人等)运动特征的查询向量,每个 Agent Query 用来捕捉交通参与者的状态信息,如位置、速度、加速度、方向等。论文采用一组可学习的向量,首先进行self-attention,获得agent-agent之间的交互,然后query与BEV特征和更新的map queries进行交叉注意力,其中与BEV特征进行交叉注意力采用deformable attention的方法,最终获得输出的特征向量AxD。经过运动预测head输出维度为300x6x12,300个目标,每个目标6个模态,每个模态6帧,每帧2个坐标点。
交互式规划
在预测模块之后,VAD 使用一个规划模块来为自车(ego vehicle)规划一条可行的轨迹。与预测模块中用于运动建模的 Motion Queries 相似,引入了一个专用于 ego vehicle 的查询向量,称为 Ego Query,它被输入到一个新的 Transformer 解码器中,用于轨迹规划。为了捕捉自车与其他交通参与者之间的相互作用(agent-agent interaction),将预测模块中输出的 Motion Queries 作为上下文(context)输入到规划模块的解码器中。该机制允许 ego vehicle 考虑其他交通参与者的未来意图,并进行反应。论文采用一组可学习的向量,维度为
,其中
表示时间步数,如取6。
先进行self-attention,然后ego-agent和ego-map分别进行cross-attention,输出维度为
。经过轨迹规划head,输出为3*6*2,3个模态,每个莫模态6个时间步,每步2个坐标点,其中3个模态论文中设定为右转、左转和直行。
3. 总结
论文探索了一种完全向量化的驾驶场景表示方法,以及如何有效地将这种向量化场景信息融合到系统中以提升自动驾驶的规划性能。VAD 同时达成了高性能与高效率的结合,使用 NVIDIA GeForce RTX 3090 GPU,VAD-Tiny推理时间在50-60ms之间。此外,VAD 支持对其他动态交通参与者的多模态运动轨迹预测。与此同时,如何将更多的交通信息(例如:车道图、交通标志、信号灯、限速信息等)融入此类自动驾驶系统,也是一个具有发展前景的研究方向。